2 When Classical Architecture Design Loops Break
TipWhat this chapter gives you
After this chapter you can:
- recognize design-loop pressure, the scissors gap between choices and trusted feedback, in a real architecture setting;
- explain why the bottleneck is trusted feedback, not idea generation;
- point to the design and verification costs that make high-fidelity feedback scarce;
- connect each pressure source to a loop field that can no longer remain implicit;
- identify where generic AI assumptions break at architecture boundaries.
Chapter 1 named Architecture 2.0 as a discipline for designing the design loop itself. It then made the claim concrete with a compact lighthouse prompt: design a low-power, RISC-V-based compute subsystem for real-time mobile XR under a 3 W, 3 nm-class low-power mobile envelope, and return a design-space report with evidence and rejected alternatives. The prompt is intentionally small. The architecture state it implies is not.
This chapter explains why that state cannot be handled by merely asking a larger model to produce a larger answer. Computer architects already use models, simulators, benchmarks, profilers, spreadsheets, compilers, RTL flows, EDA tools, and expert reviews. The problem is not the absence of tools. The problem is that the design loop that coordinates those tools is under pressure. The space to search, the constraints to satisfy, and the evidence required to trust a result now grow faster than manual coordination, review, and verification capacity.
The claim is not that the old loop is obsolete. It is that the old loop must itself become an object of design.
Design-loop pressure. Design-loop pressure is the condition in which the number of plausible actions, constraints, feedback sources, and evidence requirements grows faster than the loop’s ability to evaluate, reject, revise, and commit architecture candidates credibly.
The chapter is therefore not a technology-trend survey. Specialization, chiplets, software velocity, memory movement, EDA, physical design, and verification matter here because they create a common failure mode: the architecture team can imagine more candidates than it can evaluate, reject, and justify. Architecture 2.0 begins by making that failure mode explicit.
Read each section as a pressure test on one part of the loop. Cadence exposes gates and commitment policy. Architecture levers expand the state the loop must carry. Specialization and chiplets multiply actions. Software drift changes the workload contract. Physical constraints create early rejection conditions. Engineering cost makes feedback scarce. Generic AI assumptions fail because architecture work is not a cheap-label pipeline. Together, those pressures explain why the loop itself becomes the architecture object.
2.1 Classical Loops Already Use Feedback
Computer architecture has always been a loop. A typical loop begins with an intent: improve latency, reduce energy, raise throughput, support a workload, or fit a system into a power and cost envelope. The architect then chooses an abstraction, builds or selects a model, runs an analysis or simulation, studies the result, revises the design, and repeats. Eventually the work crosses into implementation, validation, verification, and signoff. That basic pattern is visible in textbook architecture practice and in industrial design workflows (Hennessy and Patterson 2017).
Hennessy, John L., and David A. Patterson. 2017. Computer Architecture: A Quantitative Approach. 6th ed. Morgan Kaufmann.
A traditional SPEC CPU-style study makes the loop concrete. An architect might choose a subset of SPEC CPU workloads, propose a cache hierarchy or branch predictor change, run a simulator or performance model, inspect IPC, miss rates, branch-misprediction rates, area and power proxies, reject candidates that help one workload while hurting others, and repeat. SPEC CPU 2017, for example, was designed as an industry-standardized suite for compute-intensive performance, stressing processor, memory subsystem, and compiler behavior (Standard Performance Evaluation Corporation 2017). The important point is not the specific suite version. It is the loop discipline: a bounded workload set, an explicit model, comparable metrics, rejection of weak candidates, and expert judgment about whether the evidence is strong enough.
Chapter 1 made the Architecture 1.0 to Architecture 2.0 loop shift visible in Figure 1.1. The point here is why that shift becomes necessary. Classical architecture loops already have intent, models, candidates, tool runs, and expert review. They strain when the state, action boundaries, evidence, rejection, and decision authority become too large to remain mostly implicit.
Consider a familiar cache-hierarchy exploration. The architect defines a workload set, chooses candidate cache sizes, associativities, replacement policies, and prefetching options, runs a simulator, studies miss rates, latency, bandwidth, energy, and area proxies, rejects poor candidates, and keeps iterating. Human judgment enters repeatedly: selecting workloads, deciding which proxy is credible, noticing unexpected behavior, choosing when a candidate is worth deeper analysis, and deciding which risk to accept.
This loop is powerful because it does not require perfect automation. It combines formal models, approximations, domain knowledge, and review. It also has an implicit contract: the number of choices, the cost of evaluation, and the evidence needed to make progress must remain within the capacity of the team and tools. When that contract holds, the loop works. When the contract breaks, the team may still generate ideas, but it cannot evaluate and reject them fast enough to make credible progress.
2.2 Cadence and Gates Manage Risk
Industrial architecture practice has long treated cadence as a design object. Intel’s tick-tock model is the cleanest familiar example. A “tick” moved a known microarchitecture to a new process technology; a “tock” introduced a new microarchitecture on a more mature process. The point was not that product development was literally two steps. The point was risk isolation: avoid changing every hard thing at once, preserve a cadence, and let evidence from one step inform the next. When node transitions lengthened, Intel described a move toward process-architecture-optimization, explicitly using longer-lived 14 nm and 10 nm process technologies while further optimizing products and processes to maintain product cadence (Intel Corporation 2016).
Intel Corporation. 2016. Intel Corporation 2015 Form 10-k. https://www.sec.gov/Archives/edgar/data/50863/000005086316000105/a10kdocument12262015q4.htm.
That history is useful for Architecture 2.0 because it shows that a design loop is not only a sequence of tools. It is also a policy for what is allowed to change, which evidence is strong enough to advance commitment, and how the organization reacts when feedback latency changes. Tick-tock separated process risk from microarchitecture risk. Process-architecture-optimization added an explicit optimization phase when process shrinks no longer arrived on the old schedule: instead of every generation requiring both a new process step and a new architecture step, the loop could spend another cycle improving products, libraries, physical implementation, frequency, power, and yield on a known process. In other words, the cadence changed because the feedback and commitment costs of the physical process changed. Architecture 2.0 generalizes the same lesson: if AI methods increase the rate at which candidates are proposed, the loop must become stricter about change scope, evidence gates, rejection authority, and what kind of optimization is being performed.
Other fields teach compatible lessons. EDA timing closure teaches that a late tool can reject an early abstraction. The source-backed examples later in this chapter make the pattern concrete: autotuning treats measurements as samples from a costly space, benchmark governance depends on maintained rules and comparability contracts, and control, operations, and systems engineering add the same warning in different language. A loop without observability, a decision policy, and escalation gates is not a trustworthy loop. These analogies should not displace computer architecture. They help name the reusable loop properties architects already care about: cadence, state, feedback, gates, rejection, and commitment.
This is not the first time architecture has had to redesign its loop. Table 2.1 gives a few examples. The point is not nostalgia. The point is that many ideas that once looked unmanageable became tractable only after the field made some part of the loop explicit: the interface, the rules, the workload, the tool contract, the evidence gate, or the software path.
| Shift | What the loop made explicit | Architecture 2.0 lesson |
|---|---|---|
| System/360 compatibility | A stable ISA contract separated architecture from implementation across a product family (Amdahl et al. 1964). | Architecture is a durable interface and commitment policy, not only a circuit or microarchitecture. |
| Mead–Conway VLSI and MOSIS | Design rules, layout abstractions, and fabrication access turned custom-chip design into a teachable and reusable loop (Mead and Conway 1980; USC Information Sciences Institute 2025). | Representation and access to feedback can change who can participate in architecture work. |
| RISC | Workload, compiler, VLSI, and implementation-cost assumptions became part of the architectural argument (Patterson and Ditzel 1980). | Evidence can reject attractive complexity when the full loop cost is visible. |
| SPEC-style benchmarking | Workload selection, run rules, reporting conventions, and comparability became community infrastructure (Standard Performance Evaluation Corporation 2017). | Benchmarks are loop governance, not just input programs. |
| Logic synthesis and timing closure | HDL, libraries, constraints, and timing reports gave downstream tools authority to reject upstream choices (De Micheli 1994). | Implementation feedback belongs in the architecture loop before commitment. |
| CUDA-style GPU programming | Kernels, thread hierarchies, memory spaces, libraries, and toolchains made specialized hardware programmable (Nickolls et al. 2008). | Specialized hardware succeeds only when the software loop is designed with it. |
Amdahl, Gene M., Gerrit A. Blaauw, and Frederick P. Brooks. 1964. “Architecture of the IBM System/360.” IBM Journal of Research and Development 8 (2): 87–101. https://doi.org/10.1147/rd.82.0087.
Mead, Carver, and Lynn Conway. 1980. Introduction to VLSI Systems. Addison-Wesley.
USC Information Sciences Institute. 2025. MOSIS 2.0’s First Year: Bridging Research and Production. https://www.isi.edu/news/972800/mosis-2-0s-first-year-bridging-research-and-production/.
Patterson, David A., and David R. Ditzel. 1980. “The Case for the Reduced Instruction Set Computer.” ACM SIGARCH Computer Architecture News 8 (6): 25–33. https://doi.org/10.1145/641914.641917.
Standard Performance Evaluation Corporation. 2017. SPEC CPU 2017 Benchmark. https://www.spec.org/cpu2017/.
De Micheli, Giovanni. 1994. Synthesis and Optimization of Digital Circuits. McGraw-Hill.
These examples should make the Architecture 2.0 claim less exotic. The field has repeatedly advanced by turning tacit craft into explicit loop structure. The new challenge is that AI methods can propose, search, summarize, and optimize at a scale that makes the loop state itself the bottleneck.
2.3 Architecture Levers Add State
Architecture advances by adding levers. For decades, technology scaling made the same basic design style better by providing smaller, faster, cheaper, and more energy-efficient transistors. Dennard scaling gave architects a favorable energy story as devices shrank (Dennard et al. 1974). As that story weakened, the field leaned harder on microarchitecture, instruction-level parallelism, caches, speculation, vector units, multicore, accelerators, specialization, and system-level optimization. The result is not a simple failure narrative. It is an accumulation of levers.
Dennard, Robert H., Fritz H. Gaensslen, Hwa-Nien Yu, V. Leo Rideout, Ernest Bassous, and Andre R. LeBlanc. 1974. “Design of Ion-Implanted MOSFET’s with Very Small Physical Dimensions.” IEEE Journal of Solid-State Circuits 9 (5): 256–68. https://doi.org/10.1109/JSSC.1974.1050511.
The accumulation matters because each lever creates both opportunity and obligation. Better microarchitecture adds policies and corner cases. Multicore adds coherence, synchronization, memory ordering, and workload partitioning. Specialization improves efficiency when the workload and software stack are understood, but it adds interfaces, data movement, programmability, and verification burden. Chiplets and heterogeneous integration promise modularity and scaling beyond a monolithic die, but they add partitioning, die-to-die interfaces, package-level constraints, test, yield, thermal coupling, and supply-chain questions.
Figure 2.1 summarizes the first part of the point. The field keeps adding levers because efficiency still matters. But the same moves that recover efficiency also increase the burden of representing the design state and producing trusted feedback.

The end of Dennard-style scaling and the limits of multicore scaling are not the only reasons for this pressure, but they explain why specialization became so central (Borkar and Chien 2011; Esmaeilzadeh et al. 2011). Hennessy and Patterson’s Turing Award lecture framed this moment as a new golden age for architecture, driven by domain-specific hardware/software co-design, open architectures, and agile hardware development (Hennessy and Patterson 2019). Architecture 2.0 should be read in that lineage. The opportunity inside the new golden age is to extend the quantitative method from comparing candidate artifacts to designing the data, feedback, and evidence loops that make a larger, more coupled design space tractable. In that sense, the loop becomes a first-class architecture object: something to represent, instrument, test, reject, and improve.
Borkar, Shekhar, and Andrew A. Chien. 2011. “The Future of Microprocessors.” Communications of the ACM 54 (5): 67–77. https://doi.org/10.1145/1941487.1941507.
Esmaeilzadeh, Hadi, Emily Blem, Renee St. Amant, Karthikeyan Sankaralingam, and Doug Burger. 2011. “Dark Silicon and the End of Multicore Scaling.” Proceedings of the 38th Annual International Symposium on Computer Architecture, ISCA ’11, 365–76. https://doi.org/10.1145/2000064.2000108.
Hennessy, John L., and David A. Patterson. 2019. “A New Golden Age for Computer Architecture.” Communications of the ACM 62 (2): 48–60. https://doi.org/10.1145/3282307.
That is the architectural consequence for Architecture 2.0. The new golden age gives the field more architectural levers; Architecture 2.0 asks how to govern the loop that uses them. Without that layer, AI assistance can only make the design space larger. With it, AI methods can be assigned bounded roles in search, evidence, rejection, and revision.
2.4 Specialization and Chiplets Expand Search
Specialization is attractive because efficiency is multidimensional, the point Chapter 1 made its north star. The binding constraint differs across scales, from a battery- and thermally-limited mobile part to a warehouse-scale system bounded by power delivery and total cost of ownership (Barroso et al. 2019). What this chapter adds is the consequence for the loop: specialization does not just change which metric matters, it multiplies the decisions the loop must evaluate.
Barroso, Luiz André, Urs Hölzle, and Parthasarathy Ranganathan. 2019. The Datacenter as a Computer: Designing Warehouse-Scale Machines, Third Edition. Synthesis Lectures on Computer Architecture. Springer International Publishing. https://doi.org/10.1007/978-3-031-01761-2.
Specialization increases the number of architectural decisions because the architect must decide what to specialize, where to specialize it, and how it communicates with the rest of the system. A low-power XR subsystem is not just a choice between CPU and accelerator. It raises questions about vector length, memory hierarchy, local buffers, compression, dataflow, quantization, runtime scheduling, compiler support, sensor streams, display deadlines, thermal behavior, and fallback modes.
Chiplets compound the effect. They make it possible to compose systems from multiple dies and to mix process technologies, IP blocks, and memory technologies. But a chiplet system is not simply a bigger board-level system inside a package. The package changes latency, bandwidth, energy, thermal coupling, test, repair, physical constraints, and business boundaries. Open standards such as UCIe aim to make die-to-die integration more composable by standardizing interface layers, protocols, software models, and compliance expectations (UCIe Consortium 2026). That standardization is valuable, but it also makes the architecture question more explicit: what should be partitioned, through which interface, under which evidence standard?
UCIe Consortium. 2026. UCIe Specifications. https://www.uciexpress.org/specifications.
The combinatorics are easy to understate. Suppose a team is exploring only a narrow slice of the lighthouse prompt: an accelerator and memory subsystem for one XRBench-class workload family. Even if it considers five compute organizations, four vector or accelerator interface choices, six memory hierarchy choices, four interconnect choices, three voltage/frequency policies, three compiler/runtime policies, and three verification or fidelity levels, the crude product is already:
\[ 5 \times 4 \times 6 \times 4 \times 3 \times 3 \times 3 \] That is 12,960 candidate loop states before workload versions, process corners, thermal constraints, reliability cases, and rejected configurations are counted. This number is intentionally conservative. More realistic architecture-adjacent loops quickly become much larger, or much slower, even before final silicon evidence is involved.
The product is also not just a counting problem. If each surviving state needs even a cheap analytical model, a simulator run, a synthesis check, or a human review, the loop is immediately limited by feedback cost and fidelity. Cheap models are essential, but they move the architecture problem rather than removing it: the loop must know when a proxy is good enough, when uncertainty is too wide, and when to escalate to stronger evidence. Chapter 4 turns that intuition into sample-cost and simulation-time representations, Chapter 5 separates feedback regimes by latency, fidelity, and rejection authority, and Chapter 6 returns to this same count in an evidence-gap plot that compares candidate scale with affordable high-fidelity samples.
TipField note: the small count is already a schedule
A count such as 12,960 looks harmless on the page because multiplication is cheap. It becomes an architecture problem as soon as each surviving state needs a sample: one proxy estimate, one simulator run, one synthesis check, one review meeting, or one signoff path. The loop therefore has to decide which states are screened analytically, which are replayed in simulation, which are escalated to stronger tools, and which rejected regions are worth preserving so the team does not rediscover the same dead end.
Table 2.2 grounds that pressure in concrete architecture settings. The examples are not meant to be a single measurement scale; they show that mapping, DSE, packaging, design cost, and verification each impose a different kind of loop burden.
| Loop example | Scale anchor | Loop lesson |
|---|---|---|
| DNN accelerator mapping | Timeloop’s mapspace for a 7D CNN on a 4-tiling-level architecture includes loop permutations, factorization choices, and level-bypass alternatives; the unconstrained expression contains \((7!)^4 \times (2^4)^3\) multiplied by co-factor choices (Parashar et al. 2019). | Mapping is itself a combinatorial problem; architecture evaluation depends on the mapper and its constraints. |
| DNN accelerator DSE | MAESTRO reports a design-space exploration over 480M candidate designs, identifying 2.5M valid designs at an average rate of 0.17M designs per second (Kwon et al. 2019). | Validity, pruning, and cost models are part of the evidence path, not implementation details. |
| Chip floorplanning | Google TPU-block floorplanning experiments involved up to a few hundred macros and millions of standard cells; human designers iterated for months with EDA feedback taking up to 72 h, while a reported learned method generated comparable placements in under six hours, a claim later disputed on baselines and reproducibility (Mirhoseini et al. 2021; Cheng et al. 2023). | High-fidelity feedback can be slow and multiobjective; generation is useful only when tied to tool feedback and rejection criteria. |
| Tensor-program tuning | AutoTVM describes tensor-operator search spaces on the order of billions of possible implementations for a single GPU operator (Chen et al. 2018). | The software side of specialization also has a large hardware-dependent loop. |
Parashar, Angshuman, Priyanka Raina, Yakun Sophia Shao, et al. 2019. “Timeloop: A Systematic Approach to DNN Accelerator Evaluation.” 2019 IEEE International Symposium on Performance Analysis of Systems and Software, ISPASS, 304–15. https://doi.org/10.1109/ISPASS.2019.00042.
Kwon, Hyoukjun, Prasanth Chatarasi, Michael Pellauer, Angshuman Parashar, Vivek Sarkar, and Tushar Krishna. 2019. “Understanding Reuse, Performance, and Hardware Cost of DNN Dataflows: A Data-Centric Approach.” Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, MICRO ’52, 754–68. https://doi.org/10.1145/3352460.3358252.
Mirhoseini, Azalia, Anna Goldie, Mustafa Yazgan, et al. 2021. “A Graph Placement Methodology for Fast Chip Design.” Nature 594 (7862): 207–12. https://doi.org/10.1038/s41586-021-03544-w.
Cheng, Chung-Kuan, Andrew B. Kahng, et al. 2023. “Assessment of Reinforcement Learning for Macro Placement.” Proceedings of the 2023 International Symposium on Physical Design (ISPD). https://doi.org/10.1145/3569052.3578926.
Chen, Tianqi, Lianmin Zheng, Eddie Yan, et al. 2018. “Learning to Optimize Tensor Programs.” Advances in Neural Information Processing Systems 31.
The exact size of any one space is not the point. These examples differ in task, fidelity, and tool chain, but they share the same pressure pattern: candidate count, validity, feedback cost, and evidence standards grow together. More candidates are useful only if the loop can evaluate, explain, and reject them.
2.5 Specialized Hardware Needs a Software Loop
Specialization also exposes a software obligation. It is one thing to build an accelerator, vector unit, memory hierarchy, or chiplet partition that looks efficient in isolation. It is another thing to let programmers, compilers, runtimes, libraries, and deployment systems use it without destroying the efficiency claim through data movement, synchronization, code-generation overhead, or maintenance burden.
The historical examples in Table 2.1 show the same pattern. RISC depended on a compiler story. CUDA made GPU specialization useful by making the programming and toolchain loop explicit (Nickolls et al. 2008). The tensor-program row in Table 2.2 pushes the point further: billion-scale operator search is already a software-side obligation of specialization. Systems such as Halide and MLIR make scheduling, lowering, and intermediate representations central parts of the performance loop (Ragan-Kelley et al. 2017; Lattner et al. 2020).
Nickolls, John, Ian Buck, Michael Garland, and Kevin Skadron. 2008. “Scalable Parallel Programming with CUDA.” ACM Queue 6 (2): 40–53. https://doi.org/10.1145/1365490.1365500.
Ragan-Kelley, Jonathan, Andrew Adams, Dillon Sharlet, et al. 2017. “Halide: Decoupling Algorithms from Schedules for High-Performance Image Processing.” Communications of the ACM 61 (1): 106–15. https://doi.org/10.1145/3150211.
Lattner, Chris, Mehdi Amini, Uday Bondhugula, et al. 2020. “MLIR: A Compiler Infrastructure for the End of Moore’s Law.” arXiv Preprint arXiv:2002.11054, ahead of print. https://doi.org/10.48550/arXiv.2002.11054.
For the lighthouse prompt, this means that a “64-bit RISC-V compute subsystem” cannot be judged by hardware structure alone. If the answer proposes a vector extension, custom accelerator, memory-local dataflow, or chiplet boundary, the loop must also represent how code reaches that mechanism, what compiler or runtime assumptions are required, which libraries or kernels use it, and which tests reject a design that is efficient only in a hand-written kernel. The software path is not downstream polish. It is part of the architectural claim.
2.6 Software Changes Faster than Silicon
Specialization depends on stable enough targets. But modern software stacks move quickly. AI models change. Compiler passes change. Kernel libraries change. Runtimes, serving systems, quantization formats, batching strategies, fleet policies, and benchmark versions change. The hardware design cycle does not move at the same pace.
Compiler 2.0 is a useful adjacent warning. Amarasinghe’s framing is that compilers originally made hardware disappear for programmers, but multicore processors, vector instructions, accelerators, and heterogeneous systems have pushed more performance burden back onto programmers (Amarasinghe 2020, 2026). The same pattern appears at the architecture level. Abstractions still matter, but the design loop must now expose more of the workload, software, hardware, and physical state that earlier abstractions could hide.
Amarasinghe, Saman. 2020. “Compiler 2.0: Using Machine Learning to Modernize Compiler Technology.” Proceedings of the 21st ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems. https://doi.org/10.1145/3372799.3397167.
Amarasinghe, Saman. 2026. Compiler 2.0: Building the Next Generation Compilers with Machine Learning. https://www.csail.mit.edu/event/csail-forum-saman-amarasinghe-compiler-20-building-next-generation-compilers-machine-learning.
Mattson, Peter, Hanlin Tang, Gu-Yeon Wei, et al. 2020. “MLPerf: An Industry Standard Benchmark Suite for Machine Learning Performance.” IEEE Micro 40 (2): 8–16. https://doi.org/10.1109/MM.2020.2974843.
Reddi, Vijay Janapa, Christine Cheng, David Kanter, et al. 2020. “MLPerf Inference Benchmark.” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 446–59. https://doi.org/10.1109/ISCA45697.2020.00045.
Reddi, Vijay Janapa, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, and Carole-Jean Wu. 2021. “The Vision Behind MLPerf: Understanding AI Inference Performance.” IEEE Micro 41 (3): 10–18. https://doi.org/10.1109/MM.2021.3066343.
MLPerf is a useful example because it was built to create common, reproducible machine-learning system benchmarks across a rapidly changing field (Mattson et al. 2020). MLPerf Inference sharpened the deployment-facing version of that problem: the paper reports more than 100 organizations building ML inference chips, systems spanning at least three orders of magnitude in power and five orders of magnitude in performance, and more than 600 reproducible measurements from 14 organizations in the first submission round (Reddi et al. 2020). The lesson is not only that benchmarks need rules. It is that a benchmark must encode scenarios, latency constraints, accuracy targets, software stacks, and comparability rules before performance numbers mean the same thing across systems (Reddi et al. 2021). That is also the challenge for architecture. A benchmark is not a fixed oracle. It is a maintained agreement about what evidence should count for a class of systems.
For the lighthouse prompt, the workload is not merely “XR.” It is a moving bundle of sensing, perception, graphics, display, interaction, latency, quality-of-experience, and energy constraints. XRBench provides a benchmark suite for extended-reality machine-learning workloads (Kwon et al. 2023), but a credible architecture loop must still decide which traces, model versions, deadlines, input distributions, and quality targets matter. If the software stack changes faster than the hardware loop can absorb, the design may optimize yesterday’s workload.
Kwon, Hyoukjun et al. 2023. “XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse.” Proceedings of Machine Learning and Systems.
2.7 Physical Constraints Move into Architecture
Architecture does not sit above physical reality. It is the layer where software intent, hardware mechanisms, and physical constraints become one design problem.
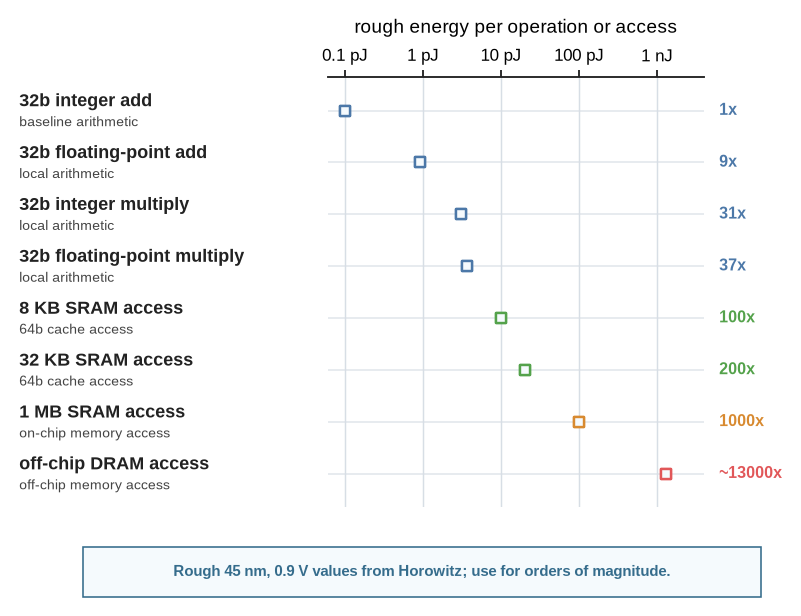
Data movement is the clearest example. Moving data through the memory hierarchy often costs far more energy than arithmetic, and Horowitz’s widely used energy estimates made this point concrete for a generation of architects (Horowitz 2014). That changes what architecture work means. A design loop cannot only ask which compute block is fastest. It must ask where the data lives, how often it moves, who schedules it, what locality exists, what precision is acceptable, and what the software stack can express.
Horowitz, Mark. 2014. “1.1 Computing’s Energy Problem (and What We Can Do about It).” 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers, 10–14. https://doi.org/10.1109/ISSCC.2014.6757323.
A useful architecture-level decomposition is \[ E_{\mathrm{system}} = E_{\mathrm{compute}} + E_{\mathrm{memory}} + E_{\mathrm{interconnect}} + E_{\mathrm{control}} + E_{\mathrm{leakage}} . \] This is not a circuit-level energy model. It is a reminder that an efficiency claim can be rejected by any term the loop failed to represent. A candidate that reduces arithmetic but increases memory movement, interconnect traffic, control overhead, or leakage has not necessarily improved the system.
Interconnect has the same character. On-chip networks, package links, memory interfaces, collectives, and host-device protocols define what a design can actually sustain. EDA and physical-design constraints also move upward. Timing, placement, routing, IR drop, thermal behavior, leakage, signoff, and test are not late implementation details when they can overturn an architectural choice. For a design loop, this means that a simulator score or model prediction is not enough. The loop needs a path from low-fidelity estimates to stronger evidence, and it needs rules for when physical constraints reject an otherwise promising candidate.
The Architecture 2.0 move is to make those physical assumptions inspectable before the loop delegates work. A generic generator can propose a faster block or a clever dataflow; an architecture loop must say which power model, memory traffic model, placement assumption, timing margin, and escalation rule make that proposal credible. Without that state, AI merely produces more candidates for a later physical-design step to reject. With that state, physical reality becomes an early design constraint, not a late surprise.
The important consequence is not that every early idea needs signoff-quality evidence. It is that the loop must know which physical assumptions are being made, what evidence would overturn them, and when to escalate from a proxy to stronger feedback. Otherwise the apparent speedup from AI-generated candidates is paid back later as discarded work.
The order-of-magnitude spread in Figure 2.2 is not something to memorize or treat as a current-node prediction. The architectural use is simpler: local arithmetic and memory movement live on very different energy scales, so a loop that optimizes only arithmetic can improve the wrong thing. Advanced-node designs do not remove this lesson; if anything, the gap between local logic and moving data, driving wires, and feeding memory systems is one reason locality remains an architectural problem rather than a solved device-scaling detail. For the 3 nm-class lighthouse prompt, the loop would need a fresh power model before making a design decision; the plot is a historical order-of-magnitude anchor, not the target-node model.
2.8 Engineering Cost Creates the Scissors Gap
The central pressure is a scissors gap. On one blade are design choices, workload variants, tool outputs, cross-layer assumptions, simulator hours, verification cases, EDA reports, physical constraints, and deployment signals. On the other blade are human attention, expert review time, tool budget, schedule, and verification capacity. The first blade rises quickly. The second does not.
Figure 2.3 makes the metaphor explicit. The upper blade is not only candidate count; it is the coupled burden of choices, constraints, evidence, software paths, and physical feasibility. The lower blade is not the ability to think; it is the slower-growing capacity to evaluate, review, reject, and commit with confidence.

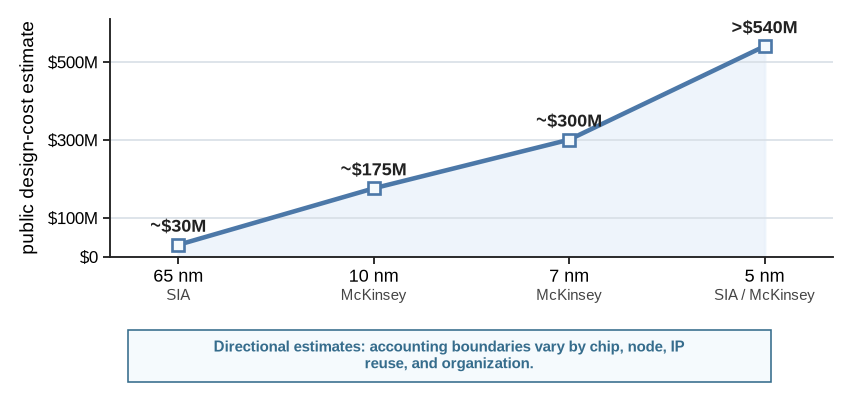
The gap is also an engineering-cost problem. Public estimates vary, and they should not be treated as universal accounting rules, but their scale is useful. The Semiconductor Industry Association reports that the cost of designing a latest-node chip rose from about $30M for a 65 nm chip in 2006 to more than $540M for a 5 nm chip in 2020, a greater-than-18x increase (Semiconductor Industry Association 2026). A McKinsey analysis gives a similar order of magnitude, estimating roughly $175M for a 10 nm design, $300M for a 7 nm design, and $540M for a 5 nm design when validation, IP qualification, and related development costs are included (Bauer et al. 2020). These are not only mask or wafer costs. They are costs of architecture, design, validation, verification, IP, tools, and people.
Verification makes the people cost visible. In a summary of the 2022 Wilson Research Group functional-verification study, Foster reports that demand for IC/ASIC verification engineers grew faster than demand for design engineers from 2007 to 2022.
The same summary reports that mean peak staffing is roughly one verification engineer per design engineer across most market segments, that processor projects can reach a 5-to-1 verification-to-design ratio, and that design engineers spent 49 percent of their time in verification in 2022 (Foster 2022). A later 2024 Wilson Research Group IC/ASIC report makes the commitment risk visible from another angle: it reports first-silicon success at 14 percent, the lowest level in two decades (Foster 2025). This is why feedback and rejection are central to Architecture 2.0. Each invalid candidate consumes scarce engineering capacity and commitment budget, not just compute cycles.
Foster, Harry. 2022. Part 8: The 2022 Wilson Research Group Functional Verification Study. Verification Horizons, Siemens EDA. https://blogs.sw.siemens.com/verificationhorizons/2022/12/12/part-8-the-2022-wilson-research-group-functional-verification-study/.
Foster, Harry. 2025. IC/ASIC Functional Verification Trend Report - 2024. Verification Academy, Siemens EDA. https://verificationacademy.com/topics/planning-measurement-and-analysis/wrg-industry-data-and-trends/2024-siemens-eda-and-wilson-research-group-ic-asic-functional-verification-trend-report/.
Figure 2.4 turns the public dollar estimates into a scale check. It should not be read as a universal cost curve. Different products, IP reuse strategies, node maturities, organizations, and accounting boundaries produce different numbers. The robust point is simpler: as the loop moves toward leading-edge implementation, feedback and commitment consume real engineering budgets, not only simulator cycles.
Semiconductor Industry Association. 2026. Chip Design and R&D. https://www.semiconductors.org/policies/chip-design/.
Bauer, Harald, Ondrej Burkacky, Peter Kenevan, Stephanie Lingemann, Klaus Pototzky, and Bill Wiseman. 2020. Semiconductor Design and Manufacturing: Achieving Leading-Edge Capabilities. McKinsey & Company report. https://www.mckinsey.com/industries/semiconductors/our-insights/semiconductor-design-and-manufacturing-achieving-leading-edge-capabilities.
This does not mean architects are ineffective. It means the unit of work has changed. An expert can reason deeply about a few candidate designs. A team can maintain a disciplined simulation and review process. But when a design space contains thousands of plausible states, when feedback arrives at multiple fidelities, and when negative results are not recorded in a reusable form, manual coordination becomes the bottleneck.
The bottleneck is trusted feedback, not ideas. Generating one more accelerator configuration, memory policy, chiplet partition, or compiler schedule is not hard. Knowing which candidates were invalid, which proxy wins disappeared at higher fidelity, which assumptions were responsible for the result, and which decision a human should commit to is the hard part.
This is the reason the scissors gap is a feedback gap rather than a creativity gap. A loop that cannot preserve failed runs, explain proxy failures, or decide when stronger evidence is required will degrade over time: future teams will rerun old mistakes, rediscover invalid regions, and mistake more output for more architectural progress.
2.9 Feedback and Verification Become the Bottleneck
Architecture feedback has uneven cost and uneven authority. A spreadsheet model is cheap but weak. A simulator may be more informative but slow or biased. A synthesis result exposes more implementation reality but depends on tool settings and constraints. Physical design and signoff are stronger still, but expensive and late. Silicon and deployment telemetry are authoritative in different ways, but they arrive after major commitments.
This feedback-regime structure makes naive autonomy dangerous. An agent that optimizes a cheap proxy may move quickly in the wrong direction. A search method that reports a Pareto frontier may hide invalid configurations, failed tool runs, or assumptions that would not survive signoff. A generated RTL fragment may look plausible but fail under verification or integration. Feedback only becomes evidence when its fidelity, provenance, uncertainty, and relevance to the decision are clear.
This is why Architecture 2.0 does not begin with autonomy. It begins with the loop. The loop must say what can be changed, what can be observed, what can reject a candidate, what evidence is strong enough for the next commitment, and what remains a human decision.
2.10 Architecture Violates Generic AI Assumptions
Many successful AI systems are built in domains with abundant data, cheap feedback, stable labels, and clear losses. Computer architecture violates that pattern at almost every boundary. Data are often proprietary, incomplete, stale, or missing the negative traces that explain why a candidate was rejected. Feedback ranges from a quick proxy to a simulation, synthesis run, physical-design report, expert review, emulation result, or silicon measurement, each with different latency, cost, fidelity, and authority. The action space is also unusual: many generated configurations are not merely low quality; they are illegal, unsupported by tools, unverifiable, or incompatible with software and physical constraints.
The result is not a simple lack of data. It is a mismatch between generic AI assumptions and architecture-loop requirements. Architecture loops need representations that carry constraints, provenance, feedback cost, uncertainty, and rejection conditions. They also need methods that understand when a proxy result is only a proxy and when a decision is moving toward a higher commitment level.
A conventional machine-learning workflow is still useful as a foil. Students often learn a pipeline that runs from data collection to preprocessing, training, validation, deployment, and monitoring. Figure 2.5 keeps that familiar picture but shows why the architecture version cannot be a simple pipeline: every step must carry validity constraints, tool costs, provenance, drift, rejected alternatives, and a human commitment gate.

The mismatch has several concrete forms. Data are not just examples; they are design artifacts with permissions, tool versions, and missing failures. Feedback is not just a label; it spans regimes such as proxies, simulation, synthesis, physical design, expert review, emulation, and silicon. Actions are not just tokens; they are edits to configuration spaces, software interfaces, RTL, constraints, and deployment policies, many of which can be invalid. Losses are not just scalar rewards; they are multiobjective efficiency claims under performance, power, area, cost, reliability, sustainability, and verification burden. Table 2.3 gives the checklist version of that argument.
| Common AI assumption | Architecture violation | Loop implication |
|---|---|---|
| Abundant labeled data | Many labels are proprietary, expensive, stale, or not recorded. | The loop must build source packets, provenance, and reusable negative traces. |
| Cheap feedback | Simulation, synthesis, EDA, emulation, and review can be slow or scarce. | Methods must be sample-efficient and aware of feedback budgets. |
| Stable distribution | Workloads, software stacks, compilers, models, and deployment policies drift. | Benchmarks and representations must be versioned and revisited. |
| Valid actions are easy to define | Many generated configurations are invalid, unsafe, unverifiable, or unsupported by tools. | Environments need action schemas, constraint checks, and rejection authority. |
| Reward is clear | Efficiency mixes performance, energy, area, cost, reliability, sustainability, verification burden, and risk. | Objectives must be explicit, multiobjective, and tied to human decisions. |
| Proxy metrics are enough | Proxy wins can vanish at higher fidelity or under different workloads. | Evidence needs fidelity-regime checks and sensitivity checks. |
| Failures are just bad samples | Failed runs, rejected candidates, and invalid states describe the design space. | Negative traces should be preserved as architecture data. |
This mismatch does not make AI irrelevant. It makes representation and loop design central. Architecture needs generation, prediction, optimization, critique, retrieval, and tool use. But those capabilities must operate inside an environment that knows what actions are legal, what feedback means, and who can say no.
2.11 AI Helps Only When the Loop Is Designed
AI becomes important because the classical loop is under pressure. It can help summarize tool outputs, propose candidates, search spaces, predict costs, construct tests, critique assumptions, retrieve prior designs, and coordinate subtasks. In domains with expensive feedback and large design spaces, even partial improvements in search, triage, and explanation can matter.
But AI is not sufficient because architecture is not only generation. The architectural problem is to produce a credible system artifact under constraints. That requires state, tools, evidence, rejection, and commitment. A model that proposes a design without exposing its assumptions has not solved the architecture problem. A workflow that finds a better proxy score without negative traces has not produced trusted evidence. A system that cannot say what rejects its own output cannot be given high-commitment authority.
The right conclusion is therefore narrower and stronger than generic AI optimism. We should not merely search larger design spaces. We should design loops that learn, record, reject, and justify architecture work. That is the transition to the ontology in the next chapter: once the pressure is visible, the next task is to name the minimum loop state that makes AI assistance inspectable rather than merely impressive.