5 Architecture Environments and Tool Interfaces
TipWhat this chapter gives you
After this chapter you can:
- turn a tool into an environment with an explicit action, observation, cost, and rejection contract;
- read a result by naming the environment that produced it;
- reason about feedback latency and fidelity as an economy of evidence;
- detect simulator mismatch and proxy gaming before they mislead the loop.
Chapter 4 argued that a loop can only act on what it represents. This chapter asks where the loop acts. In Architecture 1.0, tools often sit behind the architect: simulators, scripts, compilers, profilers, spreadsheets, RTL flows, EDA tools, dashboards, and deployment logs are the means by which a human expert gathers evidence. In Architecture 2.0, those same tools must become explicit environments. They define what actions are legal, what observations are returned, how expensive feedback is, which assumptions are baked in, what state is logged, and what can reject a candidate before it wastes more effort.
Architecture environment. An architecture environment is the explicit action boundary around tools: it specifies legal actions, observations, feedback costs, assumptions, logged state, provenance, and rejection rules for an architecture design loop.
That shift is easy to understate. A tool wrapper is not plumbing. It is a research claim about the architecture problem. It decides which parts of the design space are visible, which constraints are enforceable, which metrics are trusted, which failures are recorded, and which actions are silently impossible. A weak environment can make a strong method look useful by hiding the hard cases. A disciplined environment can make a modest method valuable by making the task bounded, repeatable, and rejectable.
The lighthouse prompt makes the point concrete. “Design a low-power, 64-bit RISC-V-based compute subsystem for an XRBench real-time mobile XR workload under a 3 W, 3 nm-class low-power mobile envelope” is not one call to one tool. It needs a workload harness, software stack, ISA and vector assumptions, candidate architecture representation, simulator or estimator, power model, compiler/runtime interface, validity checks, provenance log, and a way to record rejected alternatives. If any of those pieces are implicit, the prompt is not yet an Architecture 2.0 loop. It is only a sentence.
5.1 Tools Shape the Research Question
Computer architects have always used tools to reason quantitatively about systems. Simulators, analytic models, profilers, compilers, RTL generators, EDA flows, and measurement systems make design spaces tractable. They also shape the questions that can be asked. A simulator with a particular memory model makes some cache questions natural and others awkward. A compiler pass that exposes one schedule representation and hides another constrains what an optimizer can change. An EDA flow that returns timing and power after hours of work makes feedback precious. A runtime telemetry system that reports aggregate utilization but not per-request interference makes some deployment claims difficult to support.
The usual way to describe this is that tools have limitations. That is true, but too weak. Tools do not merely limit architecture work; they define its observable world. They decide what state exists for the loop, what actions can be applied to that state, and what feedback comes back. The classic quantitative tradition in computer architecture emphasizes measurement, abstraction, and careful comparison (Hennessy and Patterson 2017). Architecture 2.0 keeps that tradition, but it asks for one more layer of explicitness: the tool interface itself must be part of the design object.
Hennessy, John L., and David A. Patterson. 2017. Computer Architecture: A Quantitative Approach. 6th ed. Morgan Kaufmann.
This matters because agentic and learning-based methods are literal about interfaces. A human architect can sometimes infer that a simulator result is out of distribution, that a benchmark run used a stale configuration, or that a reported improvement is not meaningful because the compiler changed. A method acting through an environment will not infer those facts unless the environment represents them. The environment must expose enough state for useful action and enough constraints for safe rejection.
The right question is therefore not, “Which tool did the paper use?” The better question is, “What environment did the loop define?” That question forces the paper or project to name its workload distribution, action schema, observation schema, feedback latency, validity constraints, cost model, provenance record, and rejection rules. Once those are visible, method claims become easier to compare.
5.2 Interfaces Are Action Boundaries
Architecture is often described as the boundary between hardware and software. For Architecture 2.0, that statement has an operational meaning: interfaces are where actions become legal or illegal, observations become meaningful or misleading, and evidence becomes portable or trapped inside one tool script. An ISA, compiler IR, memory model, accelerator runtime, simulator API, benchmark harness, EDA handoff, or telemetry schema is not just a convenience for implementation. It defines what a loop can change and what can reject the change.
This is why tool interfaces belong in the architecture argument rather than in an appendix. A generator that emits a schedule must know the schedule language. A search method that changes memory hierarchy parameters must know which combinations the simulator accepts and which violate a software-visible contract. A critique system that reads a synthesis report must know which warnings are fatal, which are informational, and which require a higher-fidelity check. The interface is the boundary where method capability meets architectural validity.
Table 5.1 lists the interfaces that a credible loop often has to expose. The table is not a complete taxonomy. Its claim is that every interface has two jobs: it makes some actions possible, and it defines what evidence those actions can produce. If either side is hidden, an agent can appear capable while acting outside the architecture problem the human intended to solve.
| Interface | What it makes actionable | Evidence it makes interpretable | Failure if hidden |
|---|---|---|---|
| ISA and vector contract | Instructions, registers, vector length, exceptions, privilege, and binary compatibility. | Correct execution, portability, software-visible behavior, and compatibility tests. | The loop proposes a microarchitecture that software cannot legally target. |
| Compiler IR and schedule representation | Lowering choices, tiling, fusion, layout, vectorization, and target-specific code generation. | Compiler success, generated code, performance counters, and optimization provenance. | Performance is attributed to hardware while the software contract changed. |
| Memory and coherence model | Ordering, sharing, cacheability, consistency, DMA, and synchronization assumptions. | Correctness tests, contention behavior, latency, bandwidth, and race or ordering failures. | A candidate looks fast because it violated the program’s memory assumptions. |
| Accelerator or runtime API | Invocation, data movement, synchronization, library calls, queues, and resource ownership. | End-to-end latency, overhead, utilization, portability, and software integration cost. | Specialized hardware is efficient in isolation but unusable in the system. |
| Simulator or environment API | Legal parameters, workload inputs, observations, errors, seeds, and fidelity levels. | Comparable runs, replayable experiments, invalid-action records, and feedback cost. | The method optimizes simulator quirks or incomparable configurations. |
| EDA handoff and constraints | RTL, clocks, floorplan hints, timing constraints, power intent, physical limits, and signoff checks. | Timing, area, power, congestion, rule violations, and implementation feasibility. | A candidate survives architectural simulation but fails physical reality. |
| Benchmark harness | Inputs, versions, metrics, splits, leakage rules, and submission constraints. | Coverage, reproducibility, benchmark validity, and claim scope. | The loop overfits a stale or leaky benchmark slice. |
| Telemetry and deployment schema | Live workload mix, SLOs, counters, interference, rollout state, and drift signals. | Field behavior, regressions, rollback triggers, and post-deployment calibration. | Production evidence is rich but too confounded to support the architecture claim. |
The lighthouse prompt crosses nearly every row of the table. The phrase “64-bit RISC-V-based” invokes an ISA contract. “Vector-capable” invokes compiler and runtime obligations. “XRBench real-time mobile XR” invokes a benchmark harness, workload distribution, and quality-of-service target. “Low power” invokes power modeling, physical constraints, and eventually EDA or silicon evidence. The environment for this prompt is therefore not one API. It is a bundle of interfaces that must remain coherent as the loop proposes, checks, rejects, and revises candidates.
Concrete tools instantiate that bundle at different fidelity levels. The point is not that Architecture 2.0 requires one canonical simulator or one vendor flow. The point is that a loop must say which environment it is acting in, what that environment can observe, and what authority its feedback has. Table 5.2 gives a compact set of examples.
| Environment instance | Action boundary | Feedback and evidence | Loop lesson |
|---|---|---|---|
| gem5-style cycle or full-system simulation (Binkert et al. 2011) | Core, cache, memory-system, ISA, and workload configuration. | Statistics, traces, timing-model behavior, simulator warnings, and scoped performance comparisons. | Strong for controlled DSE; bounded by model fidelity and configuration state. |
| Verilator-style compiled RTL simulation (Veripool 2026) | RTL modules, test benches, assertions, generated C++/SystemC models, and debug hooks. | Functional behavior, waveform/debug evidence, assertion failures, and implementation-adjacent traces. | Moves closer to implementation but narrows throughput and increases debug cost. |
| FireSim-style FPGA-accelerated simulation (Karandikar et al. 2018) | RTL target, workload image, network model, FPGA mapping, and runtime configuration. | Faster cycle-exact feedback, workload-scale behavior, instrumented counters, and deployment-like experiments. | Speed changes sample economics, but setup and observability become part of the evidence. |
| Synthesis, place-and-route, and signoff flow (Mirhoseini et al. 2021; Semiconductor Industry Association 2026; Bauer et al. 2020) | RTL, constraints, floorplan hints, clocks, power intent, libraries, and process assumptions. | Area, timing, power, congestion, rule violations, waived warnings, and closure failures. | High-fidelity samples are scarce; use them as rejection gates, not blind search targets. |
Binkert, Nathan, Bradford Beckmann, Gabriel Black, et al. 2011. “The Gem5 Simulator.” ACM SIGARCH Computer Architecture News 39 (2): 1–7. https://doi.org/10.1145/2024716.2024718.
Veripool. 2026. Verilator. https://www.veripool.org/verilator/.
Karandikar, Sagar, Howard Mao, Donggyu Kim, et al. 2018. “FireSim: FPGA-Accelerated Cycle-Exact Scale-Out System Simulation in the Public Cloud.” 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), 29–42. https://doi.org/10.1109/ISCA.2018.00014.
Mirhoseini, Azalia, Anna Goldie, Mustafa Yazgan, et al. 2021. “A Graph Placement Methodology for Fast Chip Design.” Nature 594 (7862): 207–12. https://doi.org/10.1038/s41586-021-03544-w.
Semiconductor Industry Association. 2026. Chip Design and R&D. https://www.semiconductors.org/policies/chip-design/.
Bauer, Harald, Ondrej Burkacky, Peter Kenevan, Stephanie Lingemann, Klaus Pototzky, and Bill Wiseman. 2020. Semiconductor Design and Manufacturing: Achieving Leading-Edge Capabilities. McKinsey & Company report. https://www.mckinsey.com/industries/semiconductors/our-insights/semiconductor-design-and-manufacturing-achieving-leading-edge-capabilities.
Even the rows in this table hide internal ladders. Post-synthesis timing, for example, is often a useful surrogate for post-route timing, but routing congestion, IR drop, clocking, and signoff checks can still reject a candidate that looked acceptable at synthesis. The lesson is not that every loop must begin with the strongest tool. It is that the loop must know which feedback is a proxy and which later check has authority to overturn it.
This arrangement is not hypothetical. Production electronic-design-automation systems already treat the synthesis and place-and-route flow as a search environment: the action space is a set of tool directives and floorplan parameters, the transition is a full tool run, and the reward is the resulting power, performance, and area. Synopsys reported that one such reinforcement- learning system reached its first hundred commercial tapeouts by 2023 (Synopsys 2023), and Cadence describes a comparable loop driving the flow from RTL to layout (Cadence Design Systems 2021). The durable point is not which vendor leads, since the products will be renamed and replaced. It is that the EDA flow becomes an environment in exactly the sense this chapter requires once its directives are an action schema, its reports are observations, and its high-latency, high-cost runs set the feedback budget. The architect’s work then moves from running the flow by hand to specifying the environment the loop searches and the rejection gates that bound it.
Synopsys. 2023. AI-Designed Chips Reach Scale with First 100 Commercial Tape-Outs Using Synopsys Technology. Synopsys press release. https://www.prnewswire.com/news-releases/ai-designed-chips-reach-scale-with-first-100-commercial-tape-outs-using-synopsys-technology-301739936.html.
Cadence Design Systems. 2021. Machine Learning-Driven Full-Flow Chip Design Automation. Cadence Cerebrus Intelligent Chip Explorer, product white paper. https://www.cadence.com/content/dam/cadence-www/global/en_US/documents/tools/digital-design-signoff/cerebrus-wp.pdf.
5.3 The Architecture Environment Abstraction
The environment is executable, not merely descriptive. It receives a proposed action, checks whether that action is meaningful, calls one or more tools, collects observations, logs provenance, and returns feedback that can become evidence. Figure 5.1 shows the basic shape.

The abstraction can be described as a contract. The contract does not require one software framework or one programming language. It requires that the loop make a small set of obligations explicit. Table 5.3 lists the main fields.
| Field | What it defines | Question it answers |
|---|---|---|
| Workload distribution | Inputs, traces, benchmark versions, software stack, and operating scenarios. | What behavior is the design supposed to serve? |
| Action schema | Parameters, edits, configurations, generated artifacts, or commands the loop may propose. | What can the method actually change? |
| Observation schema | Metrics, traces, logs, reports, errors, and artifacts returned after an action. | What can the loop observe after acting? |
| Constraints and validity | Type checks, feasibility rules, physical limits, software compatibility, and invalid-action handling. | What makes a candidate illegal before performance is considered? |
| Feedback budget | Cost, latency, fidelity, determinism, and sample limits for each source of feedback. | How much evidence can the loop afford? |
| Provenance record | Tool versions, seeds, inputs, configuration files, assumptions, and artifact hashes. | Could a human replay or audit the result? |
| Rejection rule | Conditions that stop, revise, or escalate a candidate. | What can say no? |
The contract is deliberately broader than reinforcement learning terminology. Actions, observations, and rewards are useful terms, but architecture work also needs constraints, invalid-action semantics, provenance, and human decision points. A loop that proposes a cache size, vector width, chiplet partition, compiler flag, or RTL edit needs to know not only whether a score improved, but whether the candidate is legal, reproducible, comparable, and worth committing to a higher-fidelity stage.
For the lighthouse prompt, the environment might expose actions such as changing vector width, local memory size, issue width, cache configuration, accelerator interface, or data layout. It might return observations such as latency, throughput, estimated power, memory traffic, area proxy, simulator warnings, compiler failures, and rejected workloads. It should also return cost: how long the run took, which fidelity level was used, and how much confidence the loop should place in the feedback. Without that cost and provenance, the loop cannot reason about sample efficiency or evidence.
5.4 ArchGym as a Worked Example
ArchGym is useful because it makes the environment idea concrete in the architecture domain. It frames architecture design as a gymnasium for machine-learning-assisted design, with agents interacting with architecture environments through defined interfaces (Krishnan et al. 2023). The Architecture 2.0 gymnasium essay makes the same broader argument: the field needs data-centric environments where architecture tasks, feedback, and evaluation are exposed systematically (Janapa Reddi and Yazdanbakhsh 2023).
Krishnan, Srivatsan et al. 2023. “ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design.” Proceedings of the 50th Annual International Symposium on Computer Architecture, ISCA ’23. https://doi.org/10.1145/3579371.3589049.
Janapa Reddi, Vijay, and Amir Yazdanbakhsh. 2023. Architecture 2.0: Why Computer Architects Need a Data-Centric AI Gymnasium. ACM SIGARCH. https://www.sigarch.org/architecture-2-0-why-computer-architects-need-a-data-centric-ai-gymnasium/.
The important lesson is not that every project should use ArchGym literally. The lesson is that a shared environment changes the research question. Instead of asking whether one optimizer beat another under a private script, the community can ask which task was defined, which action space was exposed, what feedback was available, what workloads were used, and which agents or methods were compared under the same conditions. That makes method claims less anecdotal.
ArchGym also shows why the environment chapter cannot be collapsed into the methods chapter. Once an environment is defined, many methods can interact with it: Bayesian optimization, reinforcement learning, evolutionary search, surrogate-guided exploration, random search, heuristic search, or a human designer using the environment as an instrumented assistant. The environment is the common ground on which method comparisons become meaningful.
At the same time, ArchGym should not be treated as if it solves the whole Architecture 2.0 problem. A gym can still use simplified simulators. It may not include proprietary physical-design constraints, confidential workloads, tool-license behavior, workload drift, negative trace capture, or deployment telemetry. Its action spaces may be cleaner than industrial design spaces. Its feedback may be faster and more standardized than the feedback available in late-stage silicon work. Those limitations are not reasons to dismiss the environment pattern. They are reasons to make environment validity a first class concern.
5.5 Interfaces Make Loops Composable
A single tool wrapper can support one experiment. A disciplined interface can support a research ecosystem. The difference is composability. If action schemas, observation schemas, workloads, provenance records, and validity rules are explicit, then generators, predictors, optimizers, critics, verifiers, and human reviewers can be swapped or combined without rewriting the whole loop.
This is how architecture environments can become community infrastructure. Benchmarks such as MLPerf did not become useful only because they named workloads. They also created rules, versions, metrics, submissions, and comparison conventions that helped a community interpret results (Mattson et al. 2020). Architecture 2.0 needs a similar instinct at the loop level. A useful environment should not merely publish a script; it should publish the contract under which actions are legal, observations are valid, and evidence can be compared.
Mattson, Peter, Hanlin Tang, Gu-Yeon Wei, et al. 2020. “MLPerf: An Industry Standard Benchmark Suite for Machine Learning Performance.” IEEE Micro 40 (2): 8–16. https://doi.org/10.1109/MM.2020.2974843.
It is useful to reserve the word harness for this larger object. A wrapper calls a tool. A harness preserves the contract around the tool: task, workload, action schema, observation schema, cost, provenance, invalid-action semantics, negative traces, and review status. An agentic harness adds role boundaries: which component may propose, which may execute, which may critique, which may verify, and which human decision is required before escalation. The distinction matters because a wrapper can automate one experiment, but a harness can accumulate reusable knowledge about a design space.
A minimal environment record might include:
task identifier; workload version; input distribution; action fields; read-only constraints; tool commands; observation fields; fidelity level; runtime cost; random seed; tool versions; generated artifacts; failure status; rejection reason; and human decision.
That list is intentionally mundane. Mundane records are what make loops auditable. If a method proposes an architecture candidate, the environment should preserve not only the winning score but also the command that produced it, the workload revision, the tool version, the failed alternatives, the warnings, and the conditions under which the candidate would be rejected.
Composability also changes how we interpret agentic systems. A compound design system may have a planner, code generator, simulator caller, surrogate model, evidence critic, and human reviewer. Those components can coordinate only if the environment gives them a shared state representation and stable interfaces. Without that, an “agent” is merely a wrapper around a pile of scripts. With it, the loop can become an inspectable system.
5.6 Feedback Latency and Fidelity
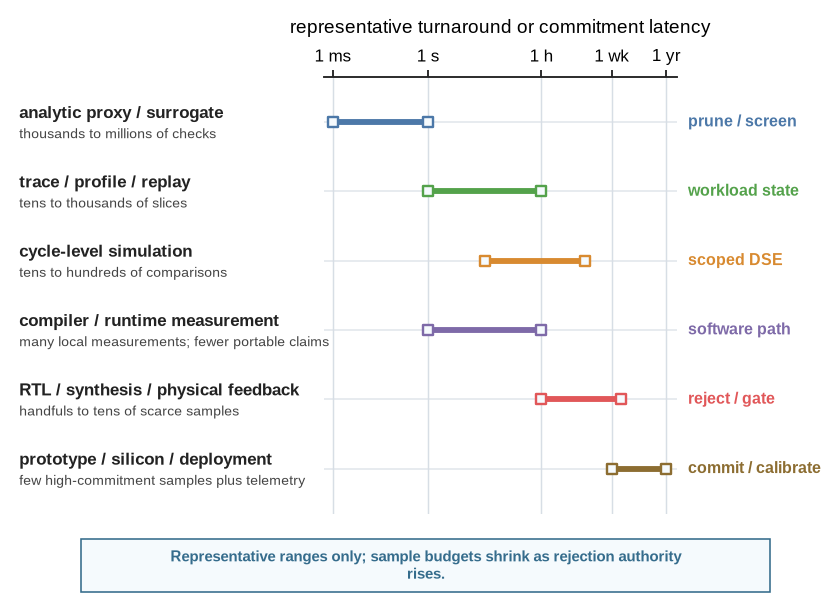
The hardest environment design choice is often not the action schema. It is the feedback regime. Architecture feedback ranges from cheap and weak to slow and authoritative. A simple analytic proxy may return in milliseconds. A cycle-level simulation may take minutes or hours, because a detailed simulator typically runs many orders of magnitude slower than the hardware it models, so seconds of target execution become hours of wall-clock time. Synthesis, place and route, or signoff of a single block are commonly hours-to-days jobs. Hardware-in-the-loop, deployment telemetry, and silicon evidence may arrive only after substantial commitment.
This creates an economy of evidence. Cheap feedback buys breadth and pruning; expensive feedback buys stronger rejection authority. Figure 5.2 shows the basic pressure: as feedback moves toward implementation and deployment, the loop usually spends more time per sample, gains less freedom to explore, and needs clearer justification for every action it takes. The ranges are representative rather than universal. A real project should replace them with its own source receipts. In the early regimes, the horizontal axis mostly means tool or measurement turnaround; near prototype, silicon, and deployment, it also includes setup, queueing, fabrication, rollout, and commitment delay.
This economy is the multi-fidelity setting studied across computational science, where cheap, lower-fidelity models are combined with scarce, high-fidelity ones to keep optimization, inference, and uncertainty quantification affordable (Peherstorfer et al. 2018). Architecture 2.0 inherits that economy and adds two architecture-specific requirements: each fidelity level must carry its own rejection authority, and a move to a higher level is a human commitment, not merely a more accurate number.
Peherstorfer, Benjamin, Karen Willcox, and Max Gunzburger. 2018. “Survey of Multifidelity Methods in Uncertainty Propagation, Inference, and Optimization.” SIAM Review 60 (3): 550–91. https://doi.org/10.1137/16M1082469.
The same pressure can be expressed as a design checklist. Table 5.4 asks what each regime can reject, how many samples the loop can plausibly afford, and what method behavior that economics permits. A loop that confuses those regimes can search quickly and still learn the wrong lesson.
| Feedback regime | Cost / latency intuition | Sample budget | What can reject | Method implication |
|---|---|---|---|---|
| Analytic proxy or learned surrogate | Milliseconds to seconds; low direct cost but high model-risk exposure. | Thousands to millions of candidate checks. | Obvious invalidity, dominated regions, sensitivity failures, or proxy-calibration failures. | Use for pruning, active learning, and broad search, not final commitment. |
| Trace, profile, or replay | Seconds to hours depending on capture, replay, and privacy filtering. | Tens to thousands of slices or scenarios. | Coverage gaps, stale workload versions, leakage, or mismatch to intended deployment. | Use for workload state, clustering, and targeted tests. |
| Cycle-level simulation | Minutes to days depending on model detail and target workload. | Tens to hundreds of scoped architecture comparisons. | Simulator configuration errors, unsupported states, calibration gaps, and sensitivity checks. | Use staged design-space exploration with replay and escalation. |
| Compiler/runtime measurement | Compilation, build, profiling: seconds to hours; target execution, replay, or autotuning: minutes to days. | Many local measurements, fewer portable claims. | Correctness tests, portability checks, and end-to-end software-path evidence. | Use autotuning or generation only with tests and provenance attached. |
| RTL, synthesis, or physical feedback | Hours to weeks when timing, power, congestion, or signoff constraints enter. | Handfuls to tens of scarce high-fidelity samples. | Timing, power, area, congestion, DRC, formal, or waived-warning review. | Use filters, surrogates, and human gates before spending samples. |
| Prototype, silicon, or deployment telemetry | High setup cost; weeks to years when field evidence or silicon commitment is required. | Few high-commitment measurements plus ongoing telemetry. | Field behavior, reliability, rollback policy, incident review, and accountable human decision. | Use for calibration, validation, and drift monitoring, not blind exploration. |
The table should also be read with a fidelity-risk rule: lower-fidelity feedback can prune and prioritize, but it can also be gamed or contradicted. When a proxy says “yes” and a stronger environment says “no,” the loop should record the mismatch instead of treating it as noise. The simulator-mismatch discussion below returns to that failure mode.
Compiler and runtime feedback have their own version of the same risk. A hardware candidate can look weak because the schedule, tiling, vectorization, layout, or runtime path is poor, not because the architecture is poor. That is a false negative created by the software side of the environment. For the lighthouse prompt, “vector-capable” therefore cannot mean only that an ISA feature exists; the loop must also expose whether the compiler and runtime can generate a credible path to use it.
This regime structure drives method choice. If feedback is cheap, broad search or online adaptation may be reasonable. If feedback is expensive, the loop needs sample efficiency, priors, surrogates, active learning, staged gates, or stronger human filtering. If feedback is high commitment, the loop should become more conservative: use AI to organize evidence, critique assumptions, and narrow the search, not to make unsupported final decisions.
The environment should therefore expose feedback budget as a first-class object. A result should not say only that candidate A beats candidate B. It should say which fidelity level produced that comparison, how many evaluations were spent, what failed, which assumptions were held constant, and what higher-fidelity check would be needed before commitment. That is the bridge from this chapter to Chapter 7.
5.7 Simulator Mismatch and Proxy Gaming
An architecture environment must also defend itself against its own abstractions. Simulators, analytical models, profilers, and compiler cost models are not neutral oracles. They encode workload choices, warm-up rules, timing models, memory-system assumptions, compiler defaults, branch predictor state, cache initialization, interconnect models, and sampling choices. A method that searches aggressively can discover weaknesses in those assumptions just as easily as it can discover a good architecture candidate.
Simulator mismatch. Simulator mismatch is the gap between the behavior an environment reports and the behavior that would matter at the next stronger fidelity level, such as a more detailed simulator, synthesis, physical design, emulation, silicon, or deployment.
The failure mode is not merely an inaccurate number. It is a loop that learns the wrong lesson. A mapping optimizer may exploit a memory model that omits contention. A compiler autotuner may win by relying on a backend assumption that changes under a different target. A hardware generator may improve a cycle-level metric while creating timing, congestion, or verification problems that the current environment cannot see. A workload harness may reward one benchmark version while hiding drift in the software stack. No simulator crash is not the same as hardware validity; the environment has to define which illegal states, unsupported configurations, and silent out-of-model behaviors it can actually reject.
TipField note: when the tool becomes the target
A common failure pattern is not that the tool is useless; it is that the loop learns exactly what the tool rewards. A candidate can improve a proxy by choosing an unsupported parameter corner, relying on a stale workload slice, or shifting cost into a compiler/runtime path the current harness does not measure. The environment should make that failure visible through invalid-action checks, baseline replay, sensitivity tests, and escalation to a stronger feedback source.
Environment design should therefore include red-team checks for the feedback source itself. A simulator-backed loop should record warm-up policy, execution- versus trace-driven mode, random seeds, sampled regions, versioned workloads, configuration files, and unsupported states. It should also include rejection tests that look for proxy gaming: cross-checks against another model, sanity constraints on bandwidth and latency, sensitivity studies, invalid-action logs, baseline replay, and escalation to stronger fidelity when the result is surprising or high commitment. The goal is not to distrust simulation. The goal is to make the simulator’s authority explicit.
5.8 Building Environments for New Subfields
A useful Architecture 2.0 environment can start small. The point is not to build a universal hardware-design platform. The point is to choose a bounded task where actions, observations, constraints, and rejection can be stated cleanly.
The recipe is straightforward.
- Define the task in architectural language: workload characterization, cache exploration, accelerator parameter search, compiler/runtime tuning, chiplet partitioning, reliability analysis, or design-review critique.
- Choose the representation the loop will read and write: configuration file, architecture description, graph, trace record, report, RTL fragment, test bench, or design-loop card.
- Define the action schema: which fields can change, which are read-only, which combinations are legal, and which changes require human approval.
- Wrap the tool path: simulator, compiler, profiler, RTL flow, EDA stage, runtime system, benchmark harness, or telemetry pipeline.
- Define observations and feedback: metrics, traces, logs, warnings, errors, generated artifacts, cost, and fidelity level.
- Define invalid-action semantics: illegal parameter, noncompilable artifact, nonsynthesizable design, violated constraint, timeout, simulator crash, or unsupported workload.
- Log provenance and negative traces: tool versions, seeds, workload versions, failed candidates, rejected alternatives, and reasons for rejection.
- State the human decision rule: what the architect reviews, what can be accepted automatically, and what must escalate.
The readiness test is simple. Could a second method, student, or research group act inside the same harness without private knowledge from the original author? Could a rejected candidate remain understandable six months later after tool versions, workload revisions, and scripts have changed? If the answer is no, the project may still contain a useful wrapper, but it has not yet produced a durable Architecture 2.0 environment.
This recipe is intentionally more operational than inspirational. It is what keeps Architecture 2.0 from becoming prompt-to-chip rhetoric. The first useful environment for a new subfield is often narrow: a bounded workload, a small action space, a clear simulator wrapper, and a disciplined log of failures. That is enough to teach the loop what it can try, what it can observe, and what evidence matters.
The lighthouse prompt suggests a good starting point. Instead of trying to build an end-to-end processor designer, start with an XRBench workload slice and a small set of candidate architectural knobs: vector width, local memory, cache size, data layout, or accelerator interface. Define which candidates are invalid, which feedback is cheap, which feedback is expensive, and what evidence would be needed to move from proxy exploration to simulator or synthesis-backed claims. That is a real Architecture 2.0 environment even if it is far from a complete chip-design system.
5.9 Environment Validity and Operating Discipline
An environment is useful only if it preserves the semantics of the architectural question. If the workload is wrong, the action space omits the important decision, the simulator hides a constraint, the proxy is uncalibrated, or the logging drops failed candidates, the loop may become more efficient at producing weak evidence.
Environment validity has several layers. The workload layer asks whether the inputs, distributions, and software stack match the intended use. The action layer asks whether the loop can change the right architectural variables without violating hidden constraints. The observation layer asks whether the returned metrics are meaningful for the claim. The fidelity layer asks whether the feedback is strong enough for the commitment being made. The provenance layer asks whether the result can be replayed or audited. The rejection layer asks what can stop a candidate when it is illegal, unsupported, misleading, or insufficiently evidenced.
Operating discipline is the practice of maintaining those layers over time. Workloads drift. Tool versions change. Compiler behavior changes. Benchmarks gain new rules. Models learn stale assumptions. A one-time environment can support a paper; a maintained environment can support a field. That is why the environment should record versions, assumptions, invalid actions, rejected candidates, and changes in the workload distribution.
ArchOps. This book proposes ArchOps, by deliberate analogy to MLOps, for the operational discipline of keeping an architecture design loop valid over time: versioning workloads and tools, recording provenance and negative traces, monitoring drift, and maintaining the rejection gates that let the loop stay trustworthy across many runs. It is the architecture counterpart of MLOps, but its artifacts are simulators, RTL, constraints, and evidence ledgers rather than models and datasets.
Naming the discipline matters because a one-time environment and a maintained one look identical on the first run and diverge completely by the tenth.
This chapter’s main claim is simple: tools become architecture environments when they expose actions, observations, costs, constraints, provenance, feedback, and rejection. Once that happens, Chapter 6 can ask which methods belong inside the loop. Without it, method choice floats free of the architecture problem. With it, generation, prediction, optimization, critique, and verification become roles inside a credible design system.