9 Loop Patterns across the Stack
After this chapter you can:
- classify an architecture task by its loop pattern and operating regime;
- match method posture and rejection authority to feedback cost and reversibility;
- explain why the same ontology carries a different evidence burden across the stack.
The previous chapters built the components of an Architecture 2.0 loop: representations, environments, method roles, feedback budgets, evidence chains, and human decision points. This chapter asks whether the framework travels. If it only describes one kind of design-space-exploration workflow, it is too narrow. If it describes everything in the same way, it is too vague. The useful middle ground is a set of loop patterns.
Loop pattern. A loop pattern is a recurring shape of architecture work with a characteristic task, representation, environment, feedback budget, evidence burden, rejection authority, and commitment level.
Workload characterization has one pattern. Fast compiler and runtime tuning has another. Accelerator, memory, interconnect, and chiplet exploration has another. Co-design across compute, memory, network, and power has another. Fleet and serving systems have another. RTL, physical design, and signoff have another. The ontology is the same, but the evidence burden changes.
This distinction protects the book from two mistakes. The first mistake is to pretend that every architecture task can be automated like a fast software loop. The second is to become so conservative that Architecture 2.0 is only a new name for old design review. The right question is more precise: given this task, representation, environment, feedback budget, and commitment level, what method roles are useful, what evidence is credible, and what can reject the result?
9.1 A Template for Reading the Cases
The cases in this chapter use one card. The card asks for the task, representation, environment, method role, feedback budget, evidence, rejection authority, human decision, failure mode, and commitment level. This keeps the chapter from becoming a list of examples. It also lets the reader compare loops that otherwise look unrelated. The lighthouse prompt remains the spine: when a separate benchmark, tool, or paper appears, it is used as a controlled slice of the prompt: workload coverage, code generation, architecture search, deployment feedback, or high-commitment physical evidence–not as a competing running example.
Figure 9.1 gives the chapter’s spectrum. The boxes are not a maturity scale. Fast software loops are not better than high-commitment loops, and high-commitment loops are not more important than workload loops. They are different operating regimes for the same ontology.

Table 9.1 is the compact comparison. The purpose is not to classify every paper perfectly. It is to force an Architecture 2.0 project to name its operating regime before choosing methods or making trust claims.
| Loop pattern | Feedback and evidence | Useful method posture | Rejection and commitment |
|---|---|---|---|
| Workload and benchmark | Traces, benchmark versions, coverage, drift, and governance. | Generate, cluster, summarize, and test workload questions. | Reject through coverage gaps, leakage, or irrelevant metrics. |
| Fast software | Unit tests, compiler/runtime results, telemetry, and quick rollback. | Higher automation for bounded search, tuning, and repair. | Reject with tests, performance regressions, or deployment guards. |
| Architecture DSE and specialization | Simulators, proxies, surrogates, compiler/runtime paths, constraints, and Pareto evidence. | Generate candidates, predict, optimize, critique, and preserve negative traces. | Reject invalid actions, proxy mismatch, software incompatibility, or weak evidence. |
| Co-design | Cross-layer models, workload traces, topology, memory, network, power, and thermal feedback. | Coordinate methods across layers and expose tradeoffs. | Reject single-layer wins that fail system objectives. |
| Systems and fleet | Deployment telemetry, canaries, drift, isolation, and operational constraints. | Adapt, monitor, critique, and revise policy under guardrails. | Reject with SLOs, safety policies, rollback, and human review. |
| RTL and physical | Formal checks, regressions, synthesis, timing, power, layout, signoff, and review. | Narrow search, organize evidence, critique, and repair bounded artifacts. | Reject with tool flows, signoff, and accountable human commitment. |
The cases that follow should be read through the same three questions. First, what are the physical constraints and rollback costs? A compiler flag, a runtime policy, an RTL edit, a chiplet boundary, and a fleet deployment do not carry the same blast radius. Second, what is the action-observation mapping? The loop should say what it can change and what tool, trace, log, or measurement it receives in return. Third, what are the rejection gates and human audit points? A case is not credible because it uses an advanced method. It is credible when the allowed actions, feedback source, evidence burden, and rejection authority match the commitment being made.
9.2 Workload Characterization and Benchmark Construction
Workload characterization is not a prelude to architecture work. It is architecture work. The workload defines what behavior matters, which metrics are meaningful, which software stack is assumed, and which design choices can be justified. Classic workload-characterization work made this concrete by measuring program behavior, comparing benchmark suites, and separating inherent workload properties from artifacts of a particular machine (Hoste and Eeckhout 2007). In Architecture 2.0, that lineage becomes loop state: trace collection, benchmark construction, workload generation, clustering, summarization, coverage analysis, drift detection, and explicit questions about what the benchmark does not represent.
The lighthouse prompt makes this concrete. “XRBench real-time mobile XR” is not a magic input string. XRBench gives the loop a benchmark anchor (Kwon et al. 2023), but the architecture question still depends on which XR workloads, models, devices, frame-rate targets, latency constraints, memory behaviors, and software paths are represented. A loop that optimizes one benchmark point may miss the distribution that a real mobile XR subsystem must serve.
MLPerf provides a useful analogy because it treats benchmarks as maintained community infrastructure, with versions, rules, and submission practices (Mattson et al. 2020). MLPerf Inference made the deployment-facing scale concrete: more than 100 organizations were building ML inference chips, systems spanned at least three orders of magnitude in power and five orders in performance, and the first submission round produced more than 600 reproducible measurements from 14 organizations (Reddi et al. 2020). The Architecture 2.0 lesson is broader: a benchmark is a living agreement about what evidence should count. A workload loop should therefore record benchmark version, workload source, coverage claims, known gaps, leakage risks, and the conditions under which a result should not generalize.
Table 9.2 makes the reframe explicit. The left column is still necessary: representative workloads, profiles, benchmark construction, and performance comparison remain central to architecture. The right columns state what changes when a method or agent is allowed to act inside the loop. The workload must become represented state, and the loop must know what evidence can reject a candidate that only wins a stale, narrow, or leaky workload slice.
| Architecture 1.0 meaning | Architecture 2.0 meaning | Loop state required | Failure if missing |
|---|---|---|---|
| Select representative workloads or benchmark suites. | Define the versioned workload distribution the loop is allowed to optimize over. | Scenario metadata, input distributions, versions, provenance, and inclusion/exclusion rationale. | The loop optimizes one stale or convenient slice and reports a false win. |
| Profile behavior: locality, branch behavior, memory traffic, bandwidth, latency, energy, and phase behavior. | Expose workload features that can drive prediction, search, critique, and active test selection. | Feature schema, measurement provenance, tool configuration, uncertainty, and known blind spots. | A predictor learns a proxy that does not survive another phase, input, or fidelity level. |
| Compare architectures under a fixed benchmark. | Maintain an evidence chain across workload variants, candidate designs, and fidelity levels. | Candidate IDs, workload IDs, simulator/tool versions, feedback cost, accepted results, and rejected results. | Design-space results cannot be audited or reused by another loop. |
| Build or curate benchmarks for community comparison. | Define an environment contract: valid tasks, inputs, actions, metrics, leakage rules, and rejection checks. | Benchmark harness, validity checks, metric definitions, seeds, test splits, and update policy. | The loop overfits benchmark artifacts or takes actions outside the intended task. |
| Explain why a workload matters. | Make workload intent, deployment context, and drift explicit enough for a human to accept or reject decisions. | Use-case assumptions, deployment constraints, QoS targets, telemetry hooks, and review notes. | The loop produces a plausible result for the wrong product or deployment regime. |
| Summarize results for a paper. | Preserve workload evidence as reusable architecture data. | Source packet, negative traces, failed runs, rejected alternatives, and rationale for final claims. | The next loop repeats invalid experiments or loses why prior choices were rejected. |
The method roles in this loop are often not glamorous. A useful agent might cluster traces, generate candidate benchmark questions, identify missing coverage, compare workload versions, or critique whether a paper’s workload supports its claim. Those roles are valuable because they improve the question the architecture loop is answering.
9.3 Fast Software Loops
Fast software loops sit near the low-commitment end of the spectrum. Compiler flags, kernels, library implementations, runtime policies, configuration settings, and small code repairs can often be evaluated quickly and rolled back. Feedback may come from unit tests, microbenchmarks, integration tests, profilers, telemetry, or canary deployment.
This is the regime where stronger automation is often plausible. Autotuning systems and learned tensor-program optimizers show how search spaces, cost models, measurements, and scheduling can be combined to improve software performance across targets (Chen et al. 2018; Zheng et al. 2020). An Architecture 2.0 loop can learn from that pattern without pretending that all hardware design is equally reversible.
Kernel-generation benchmarks make the same point in a current form. KernelBench evaluates whether models can produce GPU kernels that are both correct and faster than a baseline (Ouyang et al. 2025). This is a fast software loop because correctness tests, compilation, profiling, and microbenchmark feedback are close to the generated artifact. It also touches hardware/software co-design because performance depends on memory layout, parallelism, numerical precision, backend behavior, and target-specific hardware resources. Multi-platform kernel-generation work makes that bridge explicit by separating the core benchmark from target backends (Wen et al. 2025).
The reason autonomy can be higher here is not that the task is easy. It is that failures are often observable, bounded, and reversible. A generated kernel can be tested. A compiler flag can be reverted. A runtime policy can be canaried. A regression can be caught by a benchmark or deployment guard. Because rejection is close to the action, the loop can iterate quickly.
The failure mode is treating fast feedback as complete truth. A kernel that wins on one input size may regress another. A runtime policy that improves average latency may worsen tail latency. A compiler change that improves one benchmark may harm portability or maintainability. Even in fast loops, the card still needs workload coverage, rejection authority, and human decision when the change affects a larger system.
9.4 Architecture Loops: Accelerators, Memory, and Chiplets
Architecture design-space exploration is the canonical middle case. The loop may explore accelerator organization, vector width, cache hierarchy, local memory, interconnect, chiplet partitioning, and package assumptions. It may also choose how work is divided across CPUs, accelerators, and SoC blocks. Feedback is slower than software tests and less definitive than silicon. Actions can be invalid. Proxies can lie. The space is too large for exhaustive enumeration.
This is where the Architecture 2.0 framework feels most natural. The task is bounded but rich. The representation must expose architectural state. The environment must define legal actions and observations. Methods can generate candidates, predict behavior, optimize evaluations, critique assumptions, and preserve negative traces. ArchGym is one example of making such loops more explicit for machine-learning-assisted architecture design (Krishnan et al. 2023); predictive design-space-exploration work shows that data-driven modeling has a longer architecture lineage (Ipek et al. 2006).
Chiplets raise the stakes because they turn partitioning and interfaces into architectural decisions. Standards such as UCIe make chiplet integration more concrete (UCIe Consortium 2026), but they do not remove the architecture problem. The loop still has to reason about bandwidth, latency, power, thermal behavior, packaging, yield, verification, software contracts, and business constraints.
For the lighthouse prompt, this loop asks whether the XRBench subsystem should be a CPU extension, an accelerator, a shared-memory SoC block, or a more specialized partition. It asks which design regions are obviously infeasible, which are worth simulation, which survive power modeling, and which should be rejected before expensive evaluation. This is where candidate generation is useful, but only because the loop also records evidence and rejected alternatives.
9.5 Domain-Specific Architecture and Code Generation
Domain-specific architecture is often presented as an efficiency story: if the domain is narrower, the hardware can be more efficient. That statement is true but incomplete. A domain is not one knob. It can be a kernel family, a model family, a data type, a memory-access pattern, a programming model, a deployment regime, a latency envelope, a product vertical, or an ecosystem of libraries and tools. The golden-age argument for specialization (Hennessy and Patterson 2019) therefore creates a loop-design question: which part of the domain is stable enough to specialize, and which part must remain programmable?
Every architect knows Amdahl’s law (Amdahl 1967), so restating it adds little. The version that matters here is the one that prices the interface. Hill and Marty re-derived the law for the multicore era to show how its lesson shifts when the substrate changes (Hill and Marty 2008), and LogCA models the accelerator case directly: it makes offload latency, per-invocation overhead, and operation granularity first-class terms alongside the raw acceleration (Altaf and Wood 2017). The compact form used here keeps those costs visible: \[ S_{\mathrm{system}} \le \frac{1}{(1-f) + f/s + \epsilon_{\mathrm{interface}} + \epsilon_{\mathrm{software}}}. \] Here, \(f\) is the fraction of the end-to-end workload that the specialized mechanism can improve, \(s\) is its local speedup, and the \(\epsilon\) terms stand for the interface and software overheads that LogCA makes precise. The reading is the one LogCA emphasizes: a design pays for specialization only when the accelerated work is large enough, and coarse enough per invocation, to amortize the cost of reaching the accelerator. A dramatic local speedup can still fail as an architecture result if the stable domain fraction is small, the interface is expensive, or the software path cannot keep up.
Figure 9.2 makes the interface cost precise with the LogCA model (Altaf and Wood 2017). End-to-end speedup is not a property of the accelerator alone. It rises with the work amortized per offload, and only after that granularity clears a break-even point set by offload latency and overhead. A tightly coupled unit breaks even at small granularity; an off-chip module may need thousands of operations per call before offload is worth doing at all.
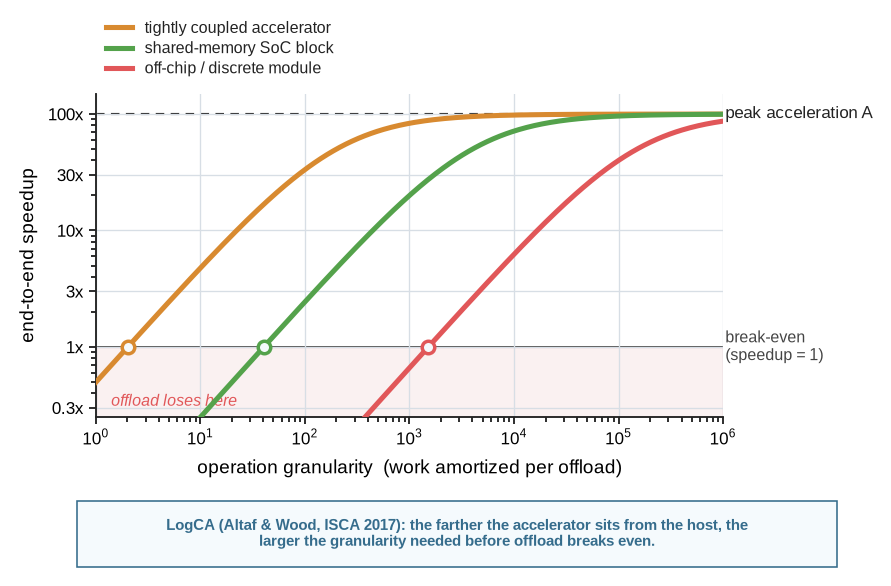
Figure 9.3 should be read as a checklist rather than a taxonomy. Before a loop proposes a domain-specific block, it should say what shape of domain it is using and what that choice implies for representation, action space, evidence, and maintenance. A benchmark name is not enough. Two workloads in the same named domain may have different memory behavior, precision contracts, software interfaces, or deployment drift.

The Achilles heel is the software path. Specialized hardware becomes useful only when computations can be expressed, mapped, compiled, tested, profiled, maintained, and revised for the target. Halide made one version of this lesson visible by separating algorithms from schedules (Ragan-Kelley et al. 2017). AutoTVM and Ansor show the same pressure in tensor-program optimization, where schedules and measurements are part of the performance story (Chen et al. 2018; Zheng et al. 2020). MLIR pushes on the infrastructure problem by making multi-level compiler representations extensible across domains and targets (Lattner et al. 2020).
Figure 9.4 makes the implication architectural: code generation is the narrow waist of specialization. Above the waist are domain intent and workload distributions. Below the waist are hardware mechanisms, tool feedback, profiling, simulation, and deployment evidence. The waist itself contains the programming model, compiler IR, libraries, runtimes, and generated code that let the workload reach the machine.

Generative methods may help at this waist, but only inside a represented loop. Kernel-generation benchmarks are encouraging precisely because they keep correctness tests, compilation, profiling, and target-specific behavior close to the generated artifact (Ouyang et al. 2025; Wen et al. 2025). For architecture, the same discipline must extend beyond one kernel: the loop needs workload semantics, data layout, scheduling constraints, backend capabilities, correctness tests, portability limits, and rejection rules. The architectural question is not only whether a specialized block is efficient. It is whether the hardware/software interface can keep that efficiency usable as workloads, models, compilers, and products change.
A specialized block posts a large kernel-level speedup and looks like a clear win. In the full system the gain mostly disappears: the compiler cannot generate code that keeps the unit busy, data movement to and from the block dominates, and only a hand-written kernel ever reached the headline number. The hardware was not wrong; the loop measured the wrong thing. This is the lesson LogCA makes precise: price the interface and the software path before believing a local speedup, and reject the candidate until a compiler-generated, end-to-end measurement survives.
9.6 Co-Design Loops: Compute, Memory, Network, and Power
Co-design loops are where the fusion-point argument becomes concrete. Architecture is not only a layer below software. It is the place where software behavior, hardware mechanisms, physical constraints, and system objectives meet. A single-layer optimization can therefore be locally correct and globally wrong.
Consider a dataflow choice that reduces compute cycles but increases memory traffic, a topology change that improves one collective while worsening another, a cache change that improves average performance but increases tail latency, or a rack-level policy that saves power while violating service quality. The loop must represent more than one layer because the objective lives across layers.
Energy is a useful reminder. Moving data, accessing memory, and operating large systems can dominate the cost of useful work; Horowitz’s energy analysis is often cited because it makes that imbalance concrete (Horowitz 2014). At datacenter scale, the system is explicitly a warehouse-scale computer, with hardware, software, power, cooling, networking, and operations coupled together (Barroso et al. 2019).
An Architecture 2.0 co-design loop therefore needs richer representations: workload phase behavior, data movement, memory locality, network behavior, power and thermal constraints, compiler/runtime choices, and deployment policy. The useful method roles are coordination and critique as much as search. The loop should ask which layer changed, which objective improved, which objective worsened, and which evidence would reject a single-layer win.
9.7 Systems Loops: Runtime, Serving, and Datacenter Policy
Systems loops evaluate architecture choices in deployed or deployment-like contexts. They include scheduling, serving, admission control, memory allocation, power management, placement, rollout policy, fleet telemetry, and performance isolation. Their feedback can be richer than simulation because it comes from real systems. It can also be noisier, more confounded, more privacy-sensitive, and harder to reproduce.
The design-loop card changes accordingly. The representation must include operational state, workload drift, service-level objectives, resource contention, customer or user constraints, and rollback mechanisms. The environment may be a simulator, test cluster, replay harness, staging system, or production system with guardrails. The method may adapt policy, detect drift, summarize telemetry, or propose a controlled experiment.
The rejection authority is often operational. A service-level objective, a canary guard, an alert, a safety policy, a privacy constraint, or a human operator can stop a rollout. This makes systems loops different from pure software loops. They may be reversible, but reversibility is not free. A bad policy can waste power, violate latency targets, create interference, or damage user experience before it is rolled back.
This pattern is important for Architecture 2.0 because architecture is increasingly evaluated through deployed behavior. A design that looks strong under a static benchmark may face different workload mixes, model versions, traffic patterns, or fleet policies. The loop must therefore connect architecture evidence to system evidence without pretending that production telemetry is a clean oracle.
9.8 High-Commitment Loops: RTL, Physical Design, and Verification
High-commitment loops stress-test the framework. RTL changes, generator-level edits, physical design, timing closure, layout, power analysis, formal verification, signoff, and silicon-facing decisions are expensive to evaluate and costly to get wrong. Feedback is delayed. Tool flows are complex. Evidence must survive independent checks. The human commitment level is high.
For the lighthouse prompt, this is the point where a candidate subsystem stops being a plausible design-space result and starts making claims that must survive RTL checks, physical constraints, power analysis, verification, and integration review.
This does not mean Architecture 2.0 is irrelevant. It means the method posture should change. In high-commitment loops, the most valuable roles may be critique, search narrowing, evidence organization, bounded repair, test generation, report summarization, and inconsistency detection. A system that finds missing assumptions, organizes tool evidence, explains why a candidate failed, or narrows a physical-design search space may be more useful than one that claims to make final autonomous decisions.
Learning-assisted chip placement is a prominent, and disputed, example of a design subflow being formulated as a learning problem (Mirhoseini et al. 2021); its baselines and reproducibility were later challenged (Chapter 7) (Cheng et al. 2023). The Architecture 2.0 lesson is not that all physical design should be handed to an agent. It is that even when learning methods help, the loop still needs tool constraints, baselines, provenance, rejection authority, and human commitment.
The regime also has documented production successes, and they sharpen the same lesson rather than contradict it. Reinforcement-learning systems that search the physical-implementation flow have reached commercial tapeouts at scale (Synopsys 2023), and reinforcement learning over a bounded circuit space produced arithmetic units that shipped in GPU silicon (Roy et al. 2021). What makes these loops credible is not the method; it is that every candidate had to pass the strongest available instrument, synthesis, timing, and signoff, before it could advance. They also surface the architect’s economic question. A search that costs many machine-hours per block is justified only when the result is amortized: a generated circuit instantiated across every shipped unit of a high-volume part repays its search cost in a way that a one-off block never could. The high-commitment regime therefore rewards methods whose cost amortizes over many uses and whose every output survives an independent gate, not methods that merely automate a single decision.
The rejection authorities in this regime are strong: parsers, type checks, regression suites, formal tools, synthesis, timing, power analysis, layout rules, signoff flows, integration review, and expert judgment. A candidate that fails here is not a near miss to be explained away. It is evidence that the loop must revise its representation, action space, method, or claim.
9.9 What Transfers across Loops
Across all of these loops, the ontology transfers. Each loop has a task, a representation, an environment, method roles, feedback, evidence, rejection, and human decision. Each loop can preserve negative traces. Each loop can be reviewed with the design-loop card. Each loop can fail by hiding assumptions, optimizing a proxy, omitting provenance, or letting an output become a decision too early.
What changes is the operating regime. Feedback latency changes. Reversibility changes. Action validity changes. Data availability changes. Security and IP constraints change. The cost of being wrong changes. Rejection authority changes. The acceptable level of autonomy changes.
Same ontology, different evidence burden. The more expensive, irreversible, or system-wide the commitment, the more the loop should shift from autonomous action toward critique, evidence organization, rejection, and human approval.
This is the practical reason to keep this chapter in the lecture. It prevents Architecture 2.0 from becoming either an abstract ontology or a paper survey. The reader should be able to take a new project and ask: Which loop pattern is this? What feedback can it afford? What representation does it need? What method roles are safe and useful? What can reject the result? What decision must remain with the architect?
The final chapter turns that question back toward professional judgment. Once the loop can be described, instrumented, acted on, and checked, what does the architect still own?
Facing a new project, ask:
- Which loop pattern is this, and what feedback can it afford?
- Does the method posture match the reversibility and blast radius of the decision?
- What can reject the result, and what decision must stay with the architect?